Model for Microservices-Oriented Email Service
Table of Contents
- Introduction
- Communication between email service and other services
- Database tables in the email service
- Logic within the email service (the engine)
- Overview of the email service model
- Advantages of this architecture
Introduction
In a microservices architecture, the email service is one of the most complex to develop due to the high degree of flexibility required to allow this service to be used by all the other available services.
The article examines the challenges related to implementing an email service in a microservices environment, considering issues such as scalability, fault tolerance, and asynchronous communication.
Communication between email service and other services
This architecture is an approach where communication between services is based on asynchronous messages or events. This allows the email service to receive a message requesting it to send an email to a specific user but enables it to first send messages to other services requesting the necessary information to generate that email.
Visualize the interaction between the email service and user service, which will be used as an example in this article:
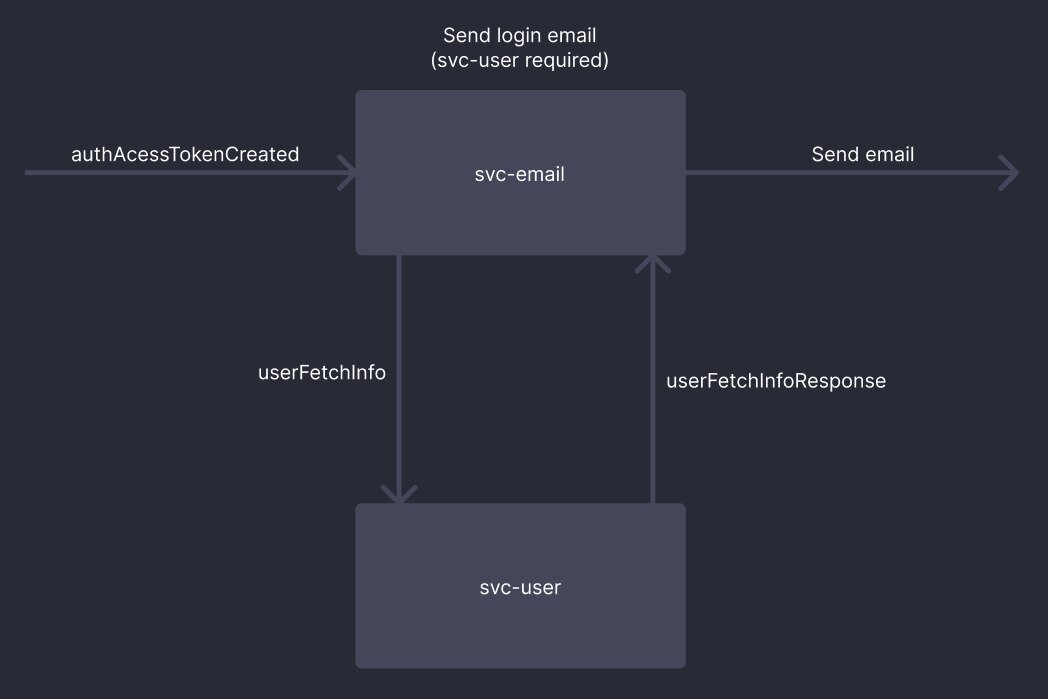
The event that triggered the email sending process is called authAccessTokenCreated. After the email service consumes this event, it triggers an event called userFetchInfo, which will be consumed by the user service. Following that, the email service waits to consume the userFetchInfoResponse event containing the requested information and is then able to correctly send the email to the user.
Database tables in the email service
Some basic tables that can serve as a foundation for illustrating how services interact with each other:

All the database tables should include some common columns. In this case, these columns are id, created_at and updated_at. The id is mandatory as it serves as the primary key for these tables. The created_at and updated_at are timestamps that represent the moment when an entry was created and updated in the table, respectively.
In the ReferenceInfo table, it is necessary to add the fields template and user_id. The template field represents the name of the template required to assemble the email. A template is a structure within the email that repeats. The user_id is required in this case to identify the user who will receive the email.
In the EmailInfo table, it is necessary to add the fields reference_id, user_id and email. The reference_id field is a foreign key that references the id in the ReferenceInfo table. The user_id serves the same purpose as in the ReferenceInfo table. The email field is the primary piece of information in this table, representing the user's email address.
In the UserInfo table, it is necessary to add the fields name and access_token. The name field represents the user's name, while the access_token field is required in this example to be the code sent to the user for use in user authentication within the system.
The main idea behind creating the ReferenceInfo table is to allow it to centralize the context behind the group of emails in the EmailInfo table by using the reference_id column. As new services are integrated with the email service, it will only be necessary to add new identifiers to the ReferenceInfo table. Examples of new identifier columns could be partner_id, customer_id, invoice_id and so on.
The relationship between the ReferenceInfo and EmailInfo tables should be one-to-many, which means that the primary key table contains only one record related to none, one, or many records in the related table.
Logic within the email service (the engine)
Within the email service, it's necessary to have a logic that checks if all the required information is available before sending emails to users. This article will refer to this logic as the engine because it resembles an engine that performs tasks to make the email machine work.
It is advisable, for good software development practices, to separate the complex logic related to the engine from the rest of the service. This is done to make it easier for new team members to isolate the common parts among all services from the specific part of the email service that deals with situations unique to that type of service.
Some details on how the engine works:
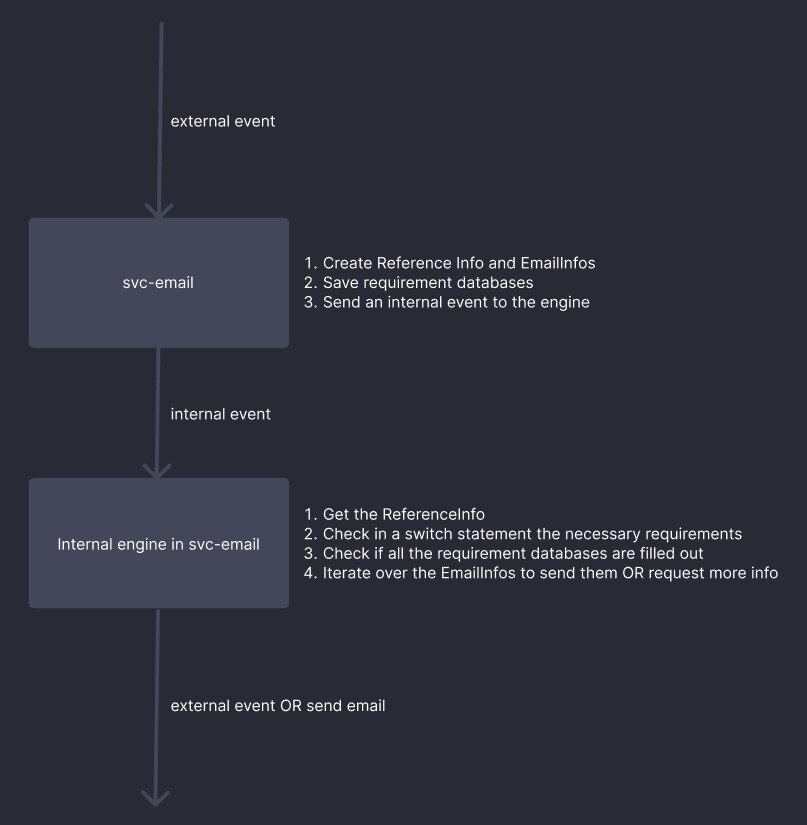
The entire process of creating emails follows a set of common instructions, making the engine completely reusable for any selected template. Without this factor, it would be necessary to employ specific logic for each group of templates, which would make the email system complex and challenging for developers to maintain.
Initially, the email service consumes the external message and populates the ReferenceInfo and EmailInfo tables in the database, as well as any other table whose information is included in the message. After that, it sends an internal message to the engine containing the logic to check if all the necessary information is available to generate the email.
The engine starts working after receiving the internal message. It then queries the ReferenceInfo table, along with the entries in EmailInfo related to that reference. Then, it checks which information is required for the reference's template and verifies if it's already saved in the database tables.
If all the necessary information is ready, the service is authorized to send the email to each user. Otherwise, the service must send an external message to the service that holds the required information, requesting whatever is needed to complete the email. Then, a cycle of message exchange is generated, returning to the email service after retrieving the required information, and then it goes through the set of instructions once again until reaching the end of the cycle. After that, it checks once more if any additional information is needed.
Caution is needed to avoid unintentionally creating an infinite cycle where the email service requests the same information thousands of times per second from various services.
Overview of the email service model
After explaining how the modules of the model work specifically and independently, it is possible to provide an overview of how this model would function:
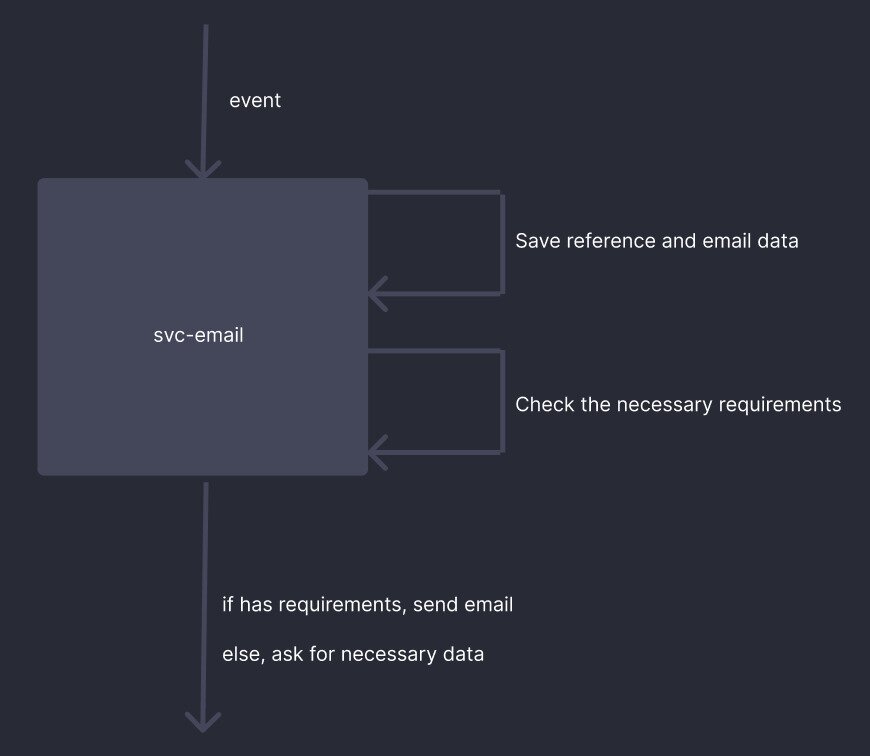
First, an external event generated by another service requests that an email should be sent to the user. The email service then saves the information contained in this message. Afterward, the service needs to check if all the necessary information is stored in the database. If it is, the service simply sends the email to the user. If not, the service sends a message to other services requesting this information. Finally, upon receiving the requested information, the service sends the email to the user.
Advantages of this architecture
One of the advantages of this approach is that if some of the external services go down for a few minutes, it's still possible for the email service to have a copy of that required data in its internal databases as caching (for example, with a 30-minute TTL controlled by an environment variable).
If that's not the case, it's possible to set up cron jobs that run periodically to monitor unsent emails and complete the process for sending emails automatically.